Project Proposal
Project Proposal
Introduction and Background
Our team is building a model to predict the outcome of NBA basketball games. More specifically, we will use data from past NBA seasons to predict the winner of a particular match-up on a certain day. The best published models in this problem space have been able to achieve within the range of 65-75% accuracy, so we will aim to reach 65% accuracy of game predictions. We will use team features such as field goal percentage, ELO (overall rating of the team), and average win-loss rate over the past 10 games. We will be training the model using game statistics over past NBA seasons, as found in datasets on Kaggle as well as scraped from the web.
Problem Definition
Data analytics and modeling has been incorporated within professional sports in order to maximize advantage. Decisions made throughout a basketball game are often influenced by these numbers and analytics, which could end up being the difference in the ultimate result of a game. Sports predictions (by analysts) is a growing industry where before every game, analysts will display a prediction as to who will win and the margin of victory. Legal betting platforms have also been expanding for years. An accurate model is imperative to predict games and quantify all metrics in a basketball game to ensure the betting process is fair. Hence, the usefulness of machine learning is only growing in sports.
Methods:
For unsupervised learning, we were planning on using GMM by grouping good, mediocre, and bad teams. PCA can also be useful as we can choose only the most important factors needed for our model. K nearest neighbors and logistic regression are supervised learning algorithms that can be useful for us because we can classify and group data points using parameters such as teams, previous games, and players. The scikit-learn library can be useful for implementing these algorithms. For example, the sklearn.neighbors module contains the KNeighborsClassifier() method that can help implement the K nearest neighbors algorithm. We would also need to normalize and preprocess the datasets in order to work with it effectively and some of the methods within the preprocessing module are Normalizer(), scale(), and MinMaxScaler().
Potential Results and Discussion
By the end of our predictions, we wish to be able to predict the winner of any given match-up based on their statistics over the past 10 games. We want to be able to see which statistics are the most important factors in determining the outcome of a game as well as how accurate our predictions about the winner are. We can use a confusion matrix as well as precision and recall metrics such as an F1 score to evaluate how often we correctly predicted the outcome of a game.
Sources:
- Baker, E. (2020, October 30). Redefining basketball positions with unsupervised learning. Medium. Retrieved February 22, 2023, from https://towardsdatascience.com/redefining-basketball-positions-with-unsupervised-learning-34988d03057
- Bunker, R. P., & Thabtah, F. (2019). A machine learning framework for sport result prediction. Applied computing and informatics, 15(1), 27-33.
- Lieder, Nachi, Can Machine-Learning Methods Predict the Outcome of an NBA Game? (March 1, 2018). Available at SSRN: https://ssrn.com/abstract=3208101 or http://dx.doi.org/10.2139/ssrn.3208101
- Loeffelholz, B., Bednar, E. & Bauer, K. (2009). Predicting NBA Games Using Neural Networks. Journal of Quantitative Analysis in Sports, 5(1). https://doi.org/10.2202/1559-0410.1156
Datesets:
- https://www.kaggle.com/datasets/nathanlauga/nba-games
- https://data.mendeley.com/datasets/x3p3fgym83
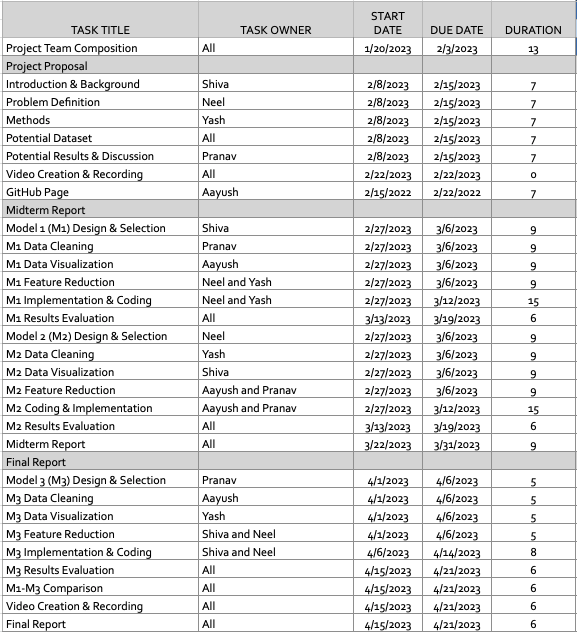
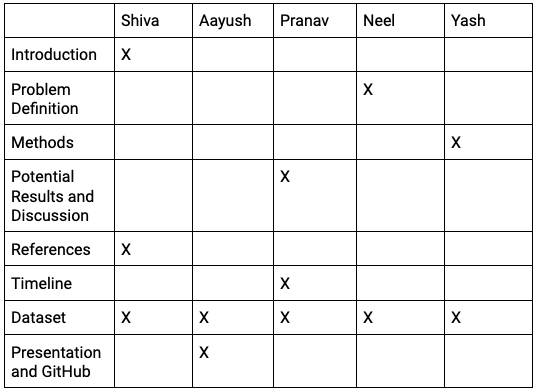
Proposal Tasks:
Timeline Preview:
- You can download and view the full timeline at this link